
浏览次数:7955 发布时间:2021-06-21-03:06:24
Transformer架构的核心是MultiHead-Attention机制。MultiHead-Attention机制涉及多个批量矩阵乘法操作,计算量比较大,需要针对实际使用的计算设备深入定制优化。因此,本次比赛希望开发并优化一个简化版本的MultiHead-Attention实现。
1、输入参数
MultiHead-Attention的输入包含以下几个:
存储布局左高右低,比如[M, N],表示N维度连续,M为高维,N为低维。
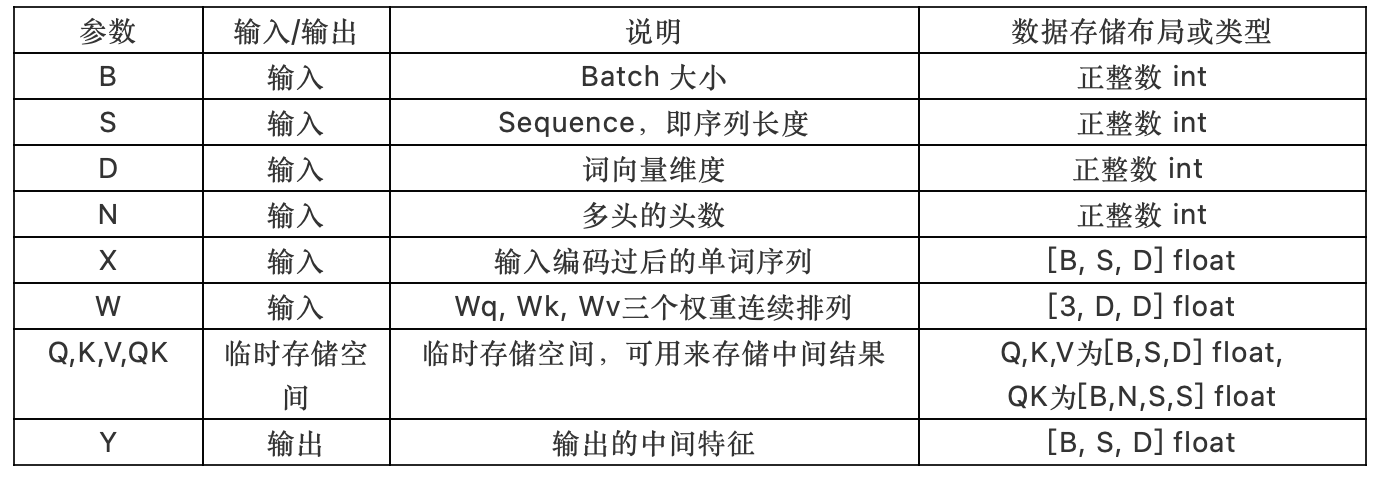
注意: W的维度[3, D, D],分别为[Wq, Wk, Wv],Wq, Wk, Wv的维度均为[D, D]
2、 算法介绍
注: * 代表矩阵乘法
1)首先,使用输入的X和W的转置分别计算Q, K, V (如图1中(a)过程),此处Wq,Wk,Wv的最低维度是与X的公共维度,即相乘累加的维度:
2)将Q, K, V转换为多头表示,为了简化,此处头的数目为(如图1中(b)过程开始部分):
以B=1, S=3, D=4, N=2为例,下图展示了MultiHead-Attention的整个计算过程:
图表 1 MultiHead-Attention的计算流程,其中B=1,S=3,D=4,为了方便展示,此处头数为2
3、 比赛参数描述
1)输入参数范围:
a)B: [1, 128]
b)S: [1, 1024],且大部分测例中S为128的倍数
c)D: 一般为768, 1024, 1280, 1536等数,使得D/N为32的倍数
d)N:一般为12, 16, 24,32等,使得D/N为32的倍数
2)参数类型:
X, W: float*,每个float均在[0.0, 1.0]区间内
Q,K,V,QK: float*,为临时空间,在计算的时候,可以用于临时存储数据
B, S, D, N : int
Y:float*
代码结构
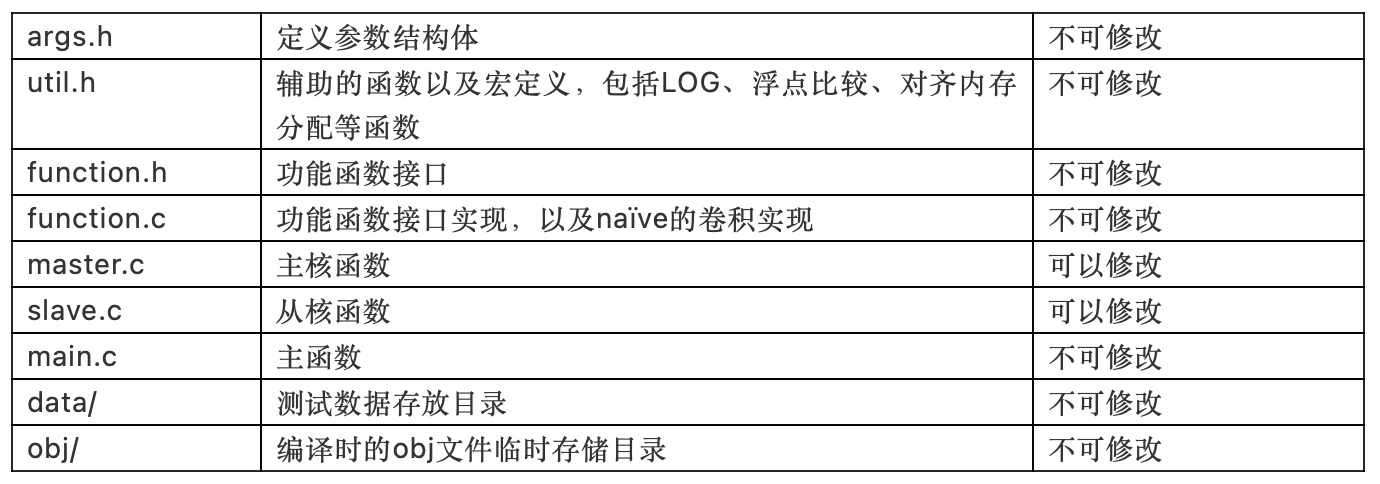
选手只能修改slave.c和master.c文件,不可对其他目录下文件进行更改。已有Makefile文件,可以直接make clean && make进行编译,make run, 即可自动执行测试,测试内容为data/目录中的数据。
程序接口
本次比赛选手需要根据官方提供的数据结构及算子设计众核加速算法,直接接口如下图所示(master.c), multihead_attention函数athread_spawn的方式调用了从核上执行par_multihead_attn(slave.c)函数,执行计算,athread_join则是等待所有的从核线程完成计算。选手需要编写、优化par_multihead_attn函数,以及有需要的时候修改multihead_attention函数,其他文件均不可修改。如果需要额外的主存空间,可以使用util.h中定义的aligned_malloc/free函数。
输入参数由官方提供,参数存储的结构体如下(args.h),如果还需要其他参数,则可以在master.c中再加入一层参数结构体定义。
为了方便理解,在function.c中提供了naïve_multihead_attention函数,为简单的串行实现,可以作为参考代码(如下图),该代码对提供的简单测试样例正确通过。该实现代码仅供参考,具体计算说明以文档为准。
data目录下存储了3个简单的供测试的数据,其中*_arg存储了参数内容,_data存储了具体数据。选手不可更改此目录及其中的文件。程序会采用多次运行取平均值的方法,获得代码的运行时间,如下所示:
1.评分规则
1) 比赛将使用组委会提供的一共十组测试样例进行测试,每组满分10分,共100分。 评分所用的测试数据与题目中提供的测试数据均不相同;对于每组测试函数,程序将运行20次,统计从核接口函数的平均运行时间;对每组平均运行时间求和,按照总运行时间进行排名计算得分,运行最快者得10分。
2) 选手必须保证计算结果的正确性,本次比赛采用绝对误差与相对误差对浮点数正确性进行判断,误差限为10的负5次方,任意一组测试函数计算结果错误,本次提交成绩无效。
3) 选手成绩取个人多次提交里面的最好成绩。
4) 如果时间一样,先提交的选手排名靠前。
5) 选手优化可以从如何切分输入张量并尽可能重用数据的角度考虑,针对不同的参数范围,其最高效的划分方式可能不同。选手着重提高代码并行计算效率和发挥申威CPU计算潜力,参赛者若修改源码中已明确不能修改部分或做其他不合理的改动将导致成绩无效。
2.编译选项
编译链接选项位于Makefile文件中,不得更改。
3.提交选项
make run
添加组委会微信,了解更多竞赛详情。



