
浏览次数:3520 发布时间:2018-07-13-10:07:00
各参赛队:
CPC2018初赛赛题公布如下:
参赛对象:CPC2018报名成功(报名邮箱收到参赛账号)的参赛队
SWLBM并行计算
程序介绍
SWLBM是一套基于格子玻尔兹曼方法(Lattice Boltzmann Method)计算流体求解程序。
格子玻尔兹曼方法是一种以速度分布函数为基本求解变量的介观数值模拟方法,通过碰撞迁移步骤来模拟流体演化过程。
本code采用LBM模型为最常用的LBGK的D3Q19模型,由钱跃竑提出。模型示意如图1所示,速度空间被分为19个方向分量。求解的控制方程如下:
![]()

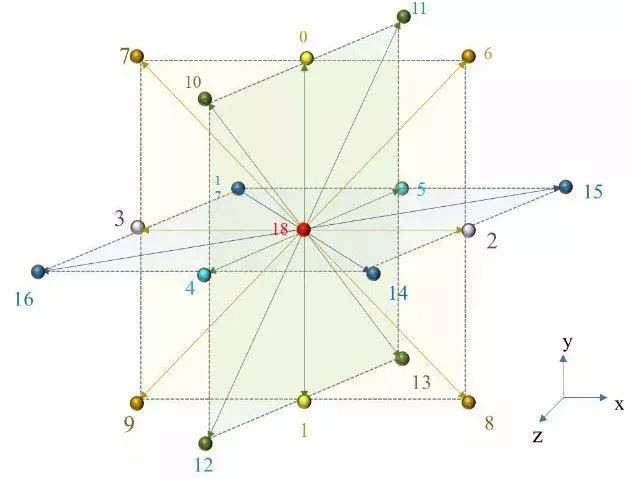
图1 D3Q19模型


变量说明:
以上理论介绍碰撞、迁移两个过程对应程序中collide和stream两个函数。
本程序计算圆柱绕流问题。流场网格类型分流体FLUID,固体SOLID,和两者的边界BOUNCE类型。用flags数组存储类型。
在程序中nodes[2][X][Y][Z][19](nodes[current][i][j][k][l])存储的即为![]() ,为以上所描述的LBM中基本求解物理量。数组第一维2,表示采用了两组
,为以上所描述的LBM中基本求解物理量。数组第一维2,表示采用了两组![]() 用于交替存储相邻两个时间步的
用于交替存储相邻两个时间步的![]() 。I,j,k为3个方向分量,l为19个分量下标。
。I,j,k为3个方向分量,l为19个分量下标。
rho变量为宏观物理量密度![]() 。
。
u_x,u_y,u_z为宏观物理速度![]() 三个方向分量。
三个方向分量。
程序中omegaNew为松弛因子![]() 的倒数,nu变量为流体物理粘性。
的倒数,nu变量为流体物理粘性。
void collide(Real *****nodes,
int ***flags,
int Xst,
int Xed,
int Yst,
int Yed,
int nz,
int current)函数
程序mpi级并行采用xy平面二维划分,传入的变量依次为nodes主求解量,flags网格类型,X,Y方向的起始终止编号,Z方向总数,current当前时间步对应编号。
void stream(Real *****nodes,
int ****walls,
int ***flags,
int Xst,
int Xed,
int Yst,
int Yed,
int nz,
int current,
int other)函数
除了传入以上collide函数描述相关信息,还传入了walls,用于判断BOUNCE点对应物面格点方向,other与current相对应的一个前一时间步对应数据标号。
Stream函数依据格点类型对FLUID和BOUNCE点分别实施操作,FLUID实现当前点与各个方向相邻点的数据交互,BOUNCE点则在遇到周边方向上是WALL时,采用自有格点数据进行交互更新,其他方向实现与相邻点交互。
u_x,u_y,u_z为宏观物理速度 SHAPE \* MERGEFORMAT
程序中omegaNew为松弛因子 SHAPE \* MERGEFORMAT
void collide(Real *****nodes,
int ***flags,
int Xst,
int Xed,
int Yst,
int Yed,
int nz,
int current)函数
程序mpi级并行采用xy平面二维划分,传入的变量依次为nodes主求解量,flags网格类型,X,Y方向的起始终止编号,Z方向总数,current当前时间步对应编号。
void stream(Real *****nodes,
int ****walls,
int ***flags,
int Xst,
int Xed,
int Yst,
int Yed,
int nz,
int current,
int other)函数
除了传入以上collide函数描述相关信息,还传入了walls,用于判断BOUNCE点对应物面格点方向,other与current相对应的一个前一时间步对应数据标号。
Stream函数依据格点类型对FLUID和BOUNCE点分别实施操作,FLUID实现当前点与各个方向相邻点的数据交互,BOUNCE点则在遇到周边方向上是WALL时,采用自有格点数据进行交互更新,其他方向实现与相邻点交互。
程序说明
1. 赛题中的网格规模(1000*500*500),算例不可改。
2. 程序的参数不可以修改,不可以修改Argument.h文件。
3. 赛题的总时间为函数TIME_ST()至TIME_ED()之间的时间,即计时区的时间,计时区:MAIN CALCULATION SECTION,不可以修改非计时区的代码,不可将优化的代码移到非计时区。
4. 网格初始化,参数初始化,结果输出的部分进行了封装(不提供源码),其不影响程序的优化, 为了各位参赛队员更好的理解程序,封装的程序做如下说明
SetParameter(): 参数的初始化
INITINPUT(): 对输入网格算例的初始化
array*(): 动态开辟空间
TIME_ST(): 计时开始
TIME_ED(): 计时结束
OUTPUT(): 输出部分
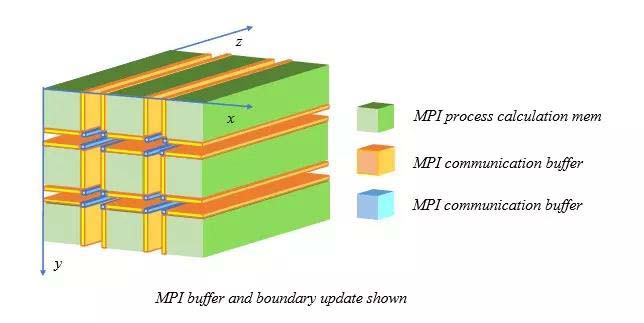
5. 本程序MPI采用二维划分(笛卡尔拓扑)方式.
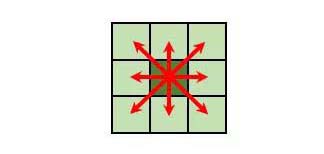
每个进程与其周围八个方向进行通信,如下图所示
为了参赛者更好地理解SWLBM的MPI通信,在Parallel.c文件里提供了SetMPI函数的实现。
注意:SetMPI函数的内容不允许修改。
6. 结果说明
程序运行的结果存放在result.dat中。
鼓励参赛队员结合国产CPU及系统结构特点对程序性能进行优化。当提交成绩到英雄榜时,脚本中包含了数个不同的测试集对优化结果进行检验,所有检验通过后才能提交成绩。
编译
直接在code目录下make即可。
$make
sw5cc -O3 -host -I/usr/sw-mpp/mpi2/include/ -lm -c LbmCavity3D.c
sw5cc -O3 -host -I/usr/sw-mpp/mpi2/include/ -lm -c Collide.c
sw5cc -O3 -host -I/usr/sw-mpp/mpi2/include/ -lm -c Parallel.c
sw5cc -O3 -host -I/usr/sw-mpp/mpi2/include/ -lm -c Stream.c
mpicc LbmCavity3D.o Collide.o Parallel.o Stream.o lib/liblbm.a -o LbmCavity3D
运行
1.参赛队优化调试期间,可选择设置makefile文件的提交脚本,make run运行。作业提交命令的最后一个参数请勿修改,否则程序将无法正常运行。
2.参赛队将成绩提交到英雄榜时,可选择运行cpcrun脚本,设置 队列名 进程数 进程数/每节点 ,如下图
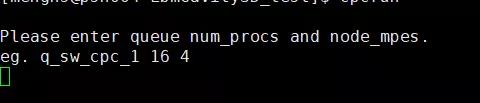
设置完成后,回车运行,运行界面如下:
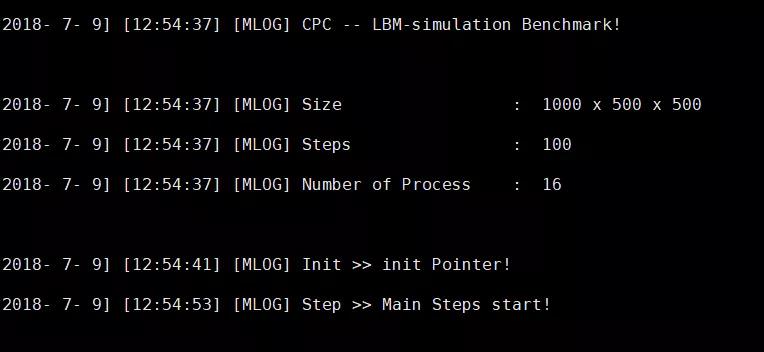
运行结束后,会给出验证结果和运行时间。
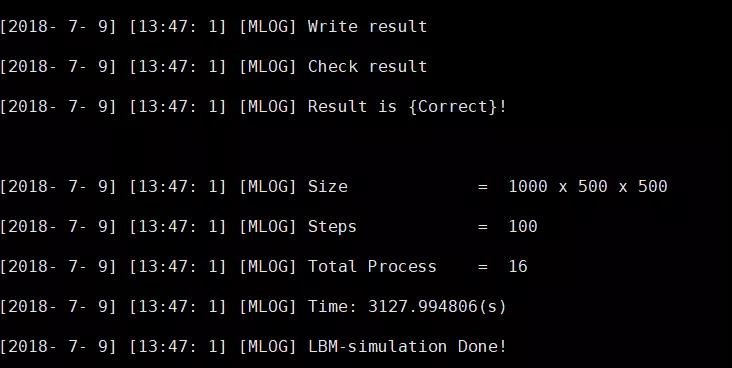
随后提示是否将当前运行的成绩提交到英雄榜。参赛队可自行选择。
硬件环境
初赛期间,为每支参赛队提供q_sw_cpc_1或q_sw_cpc_2的国产队列,配置8个节点供比赛期间测试。
注意:成绩提交到英雄榜时,作业运行的节点数不超过4个(节点数<=4)
注意
1. 赛题中的网格规模(1000*500*500),算例不可改。
2. 程序的参数不可以修改,不可以修改Argument.h文件。
3. Parallel.c的SetMPI函数不可以修改。
4. 赛题的总时间为函数TIME_ST()至TIME_ED()之间的时间,即计时区的时间,计时区:MAIN CALCULATION SECTION,不可以修改非计时区的代码,不可将优化的代码移到非计时区。
5. 精度要求:单精度的绝对误差不大于1e-6
6. 通过cpcrun脚本将优化程序的运行时间提交到英雄榜,其作业运行的节点数不超过4个(节点数<=4)
评分规则
SWLBM的总分为70分。所有参赛队伍将围绕给定的SWLBM程序进行性能优化。主办方将提供一个算例来测试参赛队伍对程序的优化效果,目标是取得最高的并行程序性能。
计分规则:总分数P的计算公式
P=70*(log(1+Tmin)/(log(1+T))
Tmin所有参赛队最小的运行时间,T表示当前参赛队的运行时间
赛题由本届大赛比赛平台提供方国家超级计算无锡中心出具
考试上机平台:神威·太湖之光
题目说明、注意事项及程序代码请于神威社区CPC2018专题板块下载:
http://bbs.nsccwx.cn/topic/107/2018年国产cpu并行应用挑战赛初赛赛题
赛制及分数比例说明
大赛共分为初赛和决赛两轮,其中,初赛部分试题分为两个部分:
第一部分:微信答题,占初赛总分30%(微信答题系统开放时间为8月6日09:00-11:00,答题时间为1个小时,请大家使用填写报名信息并提交成功的微信号登陆答题,答题时间如有变动,组委会提前发布提醒通知,敬请留意)
第二部分:上机测部分,即上述“SWLBM并行计算”题,占初赛总分70%(7月13日赛题公布,7月13日-8月15日为练习时间,8月16日-8月19日为上机测试时间,作品提交截止到为8月20日20:00,比赛成绩以最后一次提交结果为准)
初赛作品提交要求
1.提交内容:参赛队初赛期间按组委会公布的赛题答题要求(具体作品提交要求请留意大赛学习交流微信群、大赛官微CPC-HPC及大家参赛邮箱收到的cpc@paratera发送的作品提交通知),提供可执行文件及说明文档、技术报告录音PPT(5分钟)等材料,8月20日20:00前提交到大赛组委会邮箱cpc@paratera.com;
2.唯一提交方式:cpc@paratera.com ,邮件主题为: CPC2018初赛+参赛单位+队伍名称+队长姓名+联系方式。



