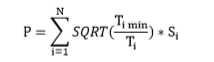浏览次数:5156 发布时间:2019-05-14-09:05:13
各参赛队,CPC2019初赛赛题公布如下:
参赛对象:CPC2019成功报名且收到参赛账号的队伍
初赛赛题:模板计算
上机平台:神威·太湖之光
模板计算是一类通过某种固定模式来更新数组元素值的迭代计算核心代码,广泛存在于科学工程计算程序中,例如求解有限差分方程,雅克比迭代,高斯-赛德尔方法等。
在均匀的各向异性的导热介质中求解热传导方程,用离散网格形式表示分布在三维空间并随时间变化的温度,那么下一个时刻一个点的温度应该取决于上一个时刻该点附近若干个点的温度。如果取决于附近7个点的温度,则相当于求解7点模板计算问题。在7点模板问题计算中,三维网格状态量g遵循迭代式
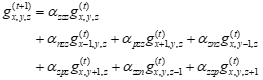
其中参数α为常数,在实际算例中指定(由于各个方向的热导率不相等,使得各个α不相等,从而不能通过提取公因式减少乘法次数)。
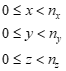
而对于超出该范围的边界,取
对输入的初始状态g(0),求经过时间T后的末状态g(T)。
问题同7点模板计算,但是迭代式变成
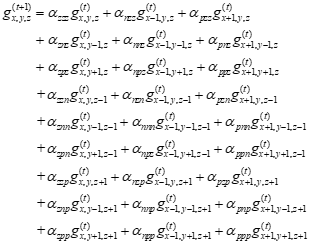
对输入的初始状态g(0),同样取零边界条件,求经过时间T后的末状态g(T)。参数α同样为常数,在实际算例中指定。
benchmark.c为主调函数,不可修改。
check.c为正确性验证程序,不可修改。
stencil-naive.c为CPU上简单串行实现,以此版本为基准进行并行,不可修改。
stencil-optimized.c 可以修改,该文件为参赛者自行实现并行版本代码。
common.h仅增加部分函数声明,关键参数不可修改。
Makefile可修改。
其他说明:
数据以x方向优先,然后y方向,最后z方向的方式存储。即x+nx*(y+ny*z)位置的元素表示gx,y,z的值。
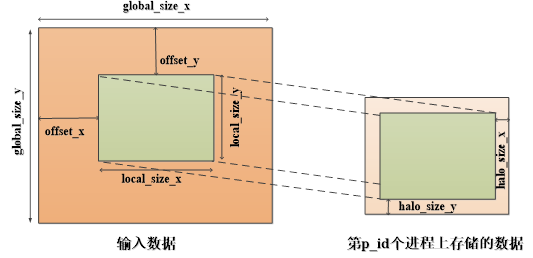
图1:数据结构
在多进程上运行时,还应该考虑分布式数据结构,每个进程存储并计算offset_x到offset_x+local_size_x、从offset_y到offset_y+local_size_y、从offset_z到offset_z+local_size_z的子块。为了处理边界网格点,在内存中存储该子块时,在六个表面保留厚度为halo_size_x、halo_size_y、halo_size_z的一圈环晕(halo),即用一个大小为local_size+2* halo_size三维数组的中心部分来存储该块。图1展示了x和y两个维度的分布式数据结构。对于单进程运行的程序,local_size=global_size,offset=0。
数据分布方式中的参数可以自己制定,即在函数create_dist_grid的实现中初始化local_size、offset和halo_size的值。create_dist_grid的第一个参数是指向数据结构信息的指针,通过该指针设置相关的值;第二个参数是模板计算类型,7表示7点模板计算,27表示27点模板计算。该函数只能拿到数据的结构信息,没有实际数据,可以做任何预处理,包括构造计算过程中使用的数据结构等。
函数stencil_7和stencil_27的前两个参数为两个指针,指向两个三维数组,大小为local_size+2*halo_size;第一个数组grid是输入数据,第二个数组aux用于存储中间结果,两个数组的环晕区均初始化为0,最后计算结构写入grid或者aux中。第三个参数包括global_size、offset、halo_size等数据结构信息;第四个参数为迭代步数。
源码:/home/export/online1/cpc/CPC_cluster.tar.gz
参赛队拷贝到自己目录下后解压缩:tar -xvzf CPC_cluster.tar.gz
输入及对比数据文件:/home/export/online1/cpc/pre,参赛队无需拷贝。
在CPU_cluster目录下:
$ make 编译benchmark-naïve及benchmark-optimized
$ make benchmark-naïve 编译benchmark-naïve
benchmark-naïve为原始可执行程序,了解程序算法及计算,不计算成绩。
$make benchmark-optimized 编译benchmark-optimized
benchmark-optimized为参赛者优化版本,计算成绩。
运行脚本示例参见CPC_cluster/run.sh
脚本包含8个参数,包括进程数、可执行程序、7/27模板计算、SIZE、SIZE、SIZE、NSTEPS 、输入数据文件、结果对比文件。run.sh运行16进程,7点stencil,512*512*512网格规模,16迭代步,输入文件为/home/export/online1/cpc/pre/stencil_data_512x512x512,计算结果对比文件为/home/export/online1/cpc/pre/stencil_answer_7_512x512x512_16steps,前台提交示例如下:
bsub -b -I -q q_sw_expr -host_stack 1024 -share_size 4096 -n 16 -cgsp 64 ./benchmark-naïve 7 512 512 512 16 /home/export/online1/cpc/pre/stencil_data_512x512x512 /home/export/online1/cpc/pre/stencil_answer_7_512x512x512_16steps 2>&1 | tee run.log
如需运行其他配置的算例,请对应修改提交命令行中的参数。
赛题的计时区时间为模板计算stencil_7 /27调用前后(start = MPI_Wtime(); end = MPI_Wtime(); )之间的时间。程序运行结束时会打印Computation time,即16迭代步模板计算时间以及程序计算性能。
为了检验结果正确性,请不要修改common.h中宏定义的α系数值。使用双精度浮点运算。要求在16步时最大误差(误差的无穷范数),如超过精度要求,运行报Significant numeric error。
目前输入文件有2个:stencil_data_512x512x512 及stencil_data_768x768x768 。其中768*768*768数据规模由于数据规模较大,无法采用单进程运行该数据规模,请实现多进程并行版本代码后再进行相关的性能测试。
结果对比文件有4种,分别为stencil_answer_7_512x512x512_16steps,stencil_answer_27_512x512x512_16steps,stencil_answer_27_768x768x768_16steps。
目前输入及对比文件均放置在/home/export/online1/cpc/pre/目录下,参赛者无需拷贝,运行时添加路径即可访问。
在原始串行代码基础上实现并优化MPI+Athread/OpenACC的7点模板计算和27点模板计算,共运行16次迭代步,获得最高的浮点计算性能。请在规则允许范围内实现高效的MPI并行和众核并行代码,仅允许修改规定源代码文件(参考代码框架部分内容),着重提高代码并行计算效率和发挥申威CPU计算潜力,不合理的改动例如修改迭代步数,修改结果验证环节等将导致成绩无效。
Ø 初赛期间,为每支参赛队提供q_sw_cpc_1或q_sw_cpc_2的国产队列,每支参赛队最多可用32个节点供比赛期间测试。
Ø 评分细则
有两种数据规模:512*512*512,768*768*768,两种模板计算:7点模板计算及27点模板计算。分别采用16进程(4个节点)和64进程(16个节点)运行代码并记录成绩。
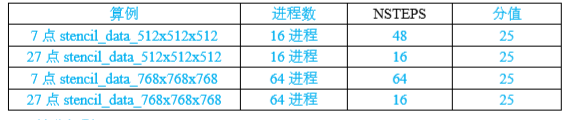
Ø 计分规则
假设N是总算例个数,Si代表第i个算例的分值,那么总分数P的计算公式如下